Film: Global-scale Image Storage with Order(s) of Magnitude Less Space
Wolfgang Richter
- 15 February 2021
- 7 minute read
Overview
What if we could store 10-100x more photos? How many more memories would we keep? How many new applications would we invent? Soroco’s Film, a state-of-the-art image storage system, is a landmark rethinking of the storage stack for modern computer vision, machine learning, and web serving workloads achieving out of the box measured 12x storage savings on big data image data sets and 100x potential with optimization.
That’s when we invented Film. Out of the box we achieve 12x storage reduction, and we believe that current optimizations we are researching can push that beyond 100x for our workload—achieving two orders of magnitude of on-disk storage saving.
Getting to this point required a rethink of the storage layer for image data in combination with the workloads we wanted it to serve. We essentially compress and deduplicate pixel data while maintaining required accuracy for computer vision, machine learning, and other algorithmic workloads. While we use Film for screenshots, early tests show that it works well even for general photos as sampled from data sets like ImageNet.
We have two key innovations in our state-of-the-art image storage system Film:
- Transcoding large (1,000+) groups of loosely related (temporally and spatially) images into large containers, and,
- Sorting those images by a perceptual hash to present them in an optimal order for pixel-level deduplication by a video codec
Lossy Storage is OK
Soroco is interested in machine workloads. We don’t have to show most of our images back to people, except in limited use cases. Thus, we only cared about keeping their fidelity just good enough for computer vision and related workloads. Critically, we don’t need pixel-by-pixel perfect image retrieval.
Write once randomly, read many (usually) sequentially
Our workload is write once, read many times. For our computer vision and machine learning applications, we can guarantee that the data sets are read off disk in sequential order. People-facing workloads may require random retrieval, but these were limited in our use case. We also feel that, in general, image retrieval is typically not in random order which is why caching layers often work so well. Popular images are easy to cache, and when an individual user browses their albums, we can guarantee an almost sequential retrieval pattern.
Thus, we do not need to store each image separately for quick, random access. This means we can cut down heavily on wasted file system metadata and efficiently use a larger container for the images. Similar to a column-store style database, Film collates many related images in large containers.
What we can’t control are the write patterns. We know users are likely, in our workloads, to upload many images at once or as a stream throughout the day. But, there is definitely more randomness in write patterns across a population of users.
We do have to handle fast, high volume random insertions across our user population. This means we need a scalable approach to grouping images that doesn’t slow down the write path.
Storing 12x More Pictures with Pixel Deduplication
Image similarity with duplicate pixels stuck out to us as the primary cause of wasted space on disk. Why are we storing so many duplicate pixels? Actually, we unfortunately had a pathological case with our Scout Enterprise product. Our image data was screenshots from across the enterprise. Of course, desktops within one organization all look very similar. Often they have the same desktop background. Often, enterprise users are running similar software. For example, many users may work on Microsoft Excel for many hours. All of their screenshots would contain duplicate pixels, and individual users would have large amounts of duplicate pixels as they work on the same Excel file.
So now the question becomes how will we deduplicate the pixels in massive amounts of screenshots? We very quickly realized that video codecs were a perfect solution to our problem, even though they weren’t designed to solve it. Video codecs deduplicate pixels inside frames and across multiple frames in a video stream taking advantage of temporal and spatial locality.
We chose an off-the-shelf video codec HEVC/H.265, although AV1, VP9, or any other suitable codec could be used as a drop-in replacement. Film is future proof by virtue of its modular architecture from any advancements in video codec compression techniques. We set the quality settings of the codec to a high value (we default to CRF=28). Note, one optimization is to tune CRF based on the accuracy and recall of algorithmic workloads on top of our dataset. While we are OK with lossy storage, we still need Film capable of serving user-facing workloads such as web browser rendering and still be legible for some of our Scout Enterprise features.

Figure 1. Storage container format. Many similar images are grouped together in containers, and then transcoded into a single, large video stream on disk.
We break up images and transcode them typically 1,000 at a time. However, this is a tunable parameter and could really be anything. We felt it was a good tradeoff between transcoding time, number of unprocessed files we have to cache, and our server’s capacity (CPU, memory, disk). Increasing this value slows down transcoding times requiring more CPU, and decreasing this value lowers the maximum compression possible. Very large storage systems may want to increase this value to 100,000 or even 1,000,000+ especially for archival workloads.
Storing 100x More Pictures by Optimizing Image Order with Perceptual Hashing
There is a way we can save even more across our users and their images. Obviously, with images coming in roughly chronological order for each user, a video codec will find lots of duplicate pixels. For example, when they are working in Excel for extended periods of time.
But what about across all the users using Excel? How could we save those pixels across the entire population of users? What if we sorted the images such that all of the perceptually similar images appeared in order for the video codec? How much more on disk space could we save?
It turns out, there is a subfield of hashing algorithms called perceptual hashes. Unlike the hash algorithms you are typically used to, perceptual hashes are actually designed to collide if the content of the media, such as an image, video, or audio byte stream, is perceptually similar to our senses.
Your traditional hashing algorithms, such as SHA-3, MD5, or even those designed for hash tables produce drastically different hashes for similar images. For example, even if you took the same exact picture of the Eiffel tower in Paris, but encoded it as a JPEG and a PNG, your traditional hashes of the JPEG and PNG would be completely different.

Figure 2. JPEG and PNG of flowers, their SHA-2 values, and Hamming Distance. As expected, their traditional hash values are completely different.
However, you if hash using a perceptual hash, such as one of those in the libphash library, you’d expect the hash values to be very close to each other in terms of bits. This closeness is typically measured by something like Hamming Distance.

Figure 3. JPEG and PNG of flowers, their perceptual hash values, and Hamming Distance. As expected, because they are perceptually identical, their perceptual hash values collide.
By ordering images by their perceptual hash locality, not solely temporal locality, within containers, we optimize the order of frames with identical pixels for transcoding by a video codec. This is ongoing research, and we intend to present the results soon in a published whitepaper. Early results suggest 100x in disk savings are possible when transcoding perceptually sorted image data sets.
Implementation Details and Future Work
We illustrate the two most common insertion and retrieval paths for Film in figures below. For brevity, we are not including every detail below, just the most important high-level details. A comprehensive description of Film will follow in a published white paper and open source repository.
Image Insertion

Figure 4. For fast insertion, transcoding is not on the insertion path. Clients inserting images into Film never block waiting for a transcode operation. Thus, the write path is essentially as quick as writing the image out to backing storage, and a database insert for bookkeeping.
Figure 5. Asynchronously, perceptual hashes are computed and an open container, meaning a container that has not been transcoded yet, is picked to add the image. The container is picked via a k-NN clustering algorithm. This ensures that the images are added to containers with perceptually similar images.

Figure 6.Once the container fills up, or too much time has passed with it being in an open state accepting new images, all of the images in the container undergo a final sort based on their perceptual hashes, and transcoding into their final video container file. This is the most computationally intensive stage. Similar to the second stage, it can occur asynchronously in the background.
Single and Bulk Image Retrieval
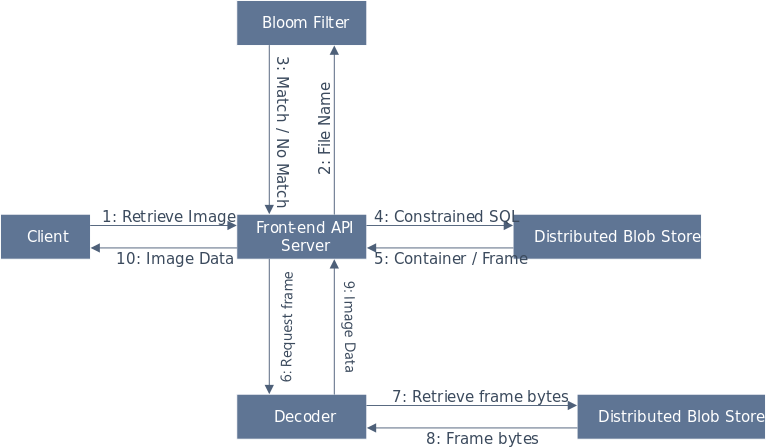
Figure 7. Single image and bulk image retrieval are similar. We use a Bloom Filter as an index for an entire cluster of images. For example, all Excel images might map into the same cluster. Clusters therefore can have multiple containers. After localizing the cluster based on cluster Bloom Filters, we then lookup using SQL queries the actual container and frame index for a requested image. The video file is decoded, ideally with a codec supporting quick random access decodes, and the requested frame is converted back into a usable image format typically JPEG for client consumption. Bulk image retrieval just inserts loops at every step for each requested image name, and an optimizer to order the decoding of video container files. For example, N images might come from one container. We can pre-compute the frames to grab, and walk through the video file in a sequential order to optimize disk read paths and video codec decoder logic.
Whitepaper and Future Work
There are many interesting facets to Film including:
- How exactly do we implement distributed k-NN clustering across the containers?
- How can we efficiently delete images from large video containers if demanded by users?
- If we can’t immediately delete images, how do we efficiently implement a compacting garbage collector for large video containers?
- What is the effect of perceptual hashing ordering on our enterprise workload and also general workloads such as ImageNet?
All of which will be explored in our upcoming whitepaper!
If you enjoy reading this article and want to work on similar problems, apply here and come work with us!
Like this article? Spread the word